Projects
Multi-Datacenter Monitoring Solution

Built a monitoring platform that’s basically a crystal ball for infrastructure problems - it knows about issues before they happen. With over 300 alerting rules watching everything from database hiccups to network sneezes, it catches problems while they’re still just bad ideas.
I designed the whole stack using VictoriaMetrics for metrics storage, Grafana for dashboards that actually make sense, and custom exporters for some pretty niche Triton SmartOS environments. The entire platform runs on Kubernetes using ArgoCD’s “Apps of Apps” pattern - no more “it works on my laptop” syndrome, everything is declarative and version-controlled. Each alert comes with its own AI-generated playbook - that’s 300+ troubleshooting guides because apparently infrastructure finds new and creative ways to break.
Under the hood:
- VictoriaMetrics Cluster
- Grafana with Azure AD SSO
- ArgoCD with Apps of Apps pattern
- k0s Kubernetes
- DirectPV storage
- sealed-secrets controller
- UpdateCLI for automated updates
- Kubernetes custom resources
- cert-manager for TLS
- ingress-nginx for routing
- custom Prometheus exporters
- VictoriaMetrics Operator
- Kustomize for manifest management
Two-day CDN Migration
![]()
Turned what should have been weeks of manual surgery into a two-day Terraform symphony. Managing 100+ domains across multiple environments used to involve a lot of prayer and sheer willpower - now it’s just code that works.
I built the whole thing with Terraform modules for DNS management and CDN configurations that made the migration repeatable and auditable. The documentation is clear enough that new team members don’t need to decipher ancient infrastructure hieroglyphics.
Under the hood:
- Terraform modules for DNS and CDN configuration
- CloudFlare API for domain management
- site redirects and security rules automation
- origin certificate management
- multi-environment domain configurations
- BetterStack monitoring integration
Terraform GitOps Conversions
![]()
No more manual configuration drift or surprise changes - everything is code-driven, version-controlled, and refreshingly predictable.
I implemented automated Terraform workflows with plans on pull requests and applies on merge, plus SOPS encryption for secrets. The CI/CD pipeline is smart enough to detect exactly what changed and only rebuild those specific components. It’s become my personal crusade to get absolutely everything possible into Terraform - if it can be automated, it should be automated.
Under the hood:
- smart CI/CD that only runs terraform for modified applications
- SOPS with Age encryption for secrets
- remote state management in S3
- automated terraform plans on pull requests
- terraform applies on merge to main branch
- reusable terraform modules
PostgreSQL Automations

Built PostgreSQL clusters that handle network hiccups like champs and have cross-datacenter replication for when things really hit the fan. Sleep is important, after all.
I wrote Ansible playbooks that know their way around database replication, automated the backup process to allow for seamless point-in-time recovery, and built monitoring that gave us many heads-ups before PostgreSQL started having a bad day.
Under the hood:
- Ansible with custom roles
- PostgreSQL with streaming replication
- Molecule testing framework
- S3-compatible backup storage
- automated user provisioning
- Ansible Vault for secrets
nsc
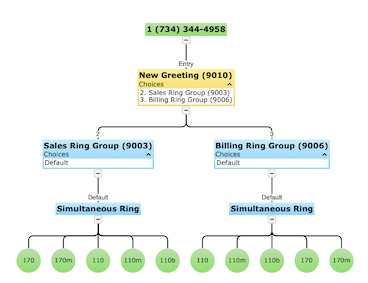
Given a phone number, the NetSapiens Console (NSC) application traverses through PBX call routes, and dynamically generates an IVR chart. NSC has saved the organization hundreds of hours over the course of many years, and it is still being used to this day as far as I know.
I wrote the backend Node.js and the front-end in React. It was the first project I ever worked on as a software engineering intern.
LingQML
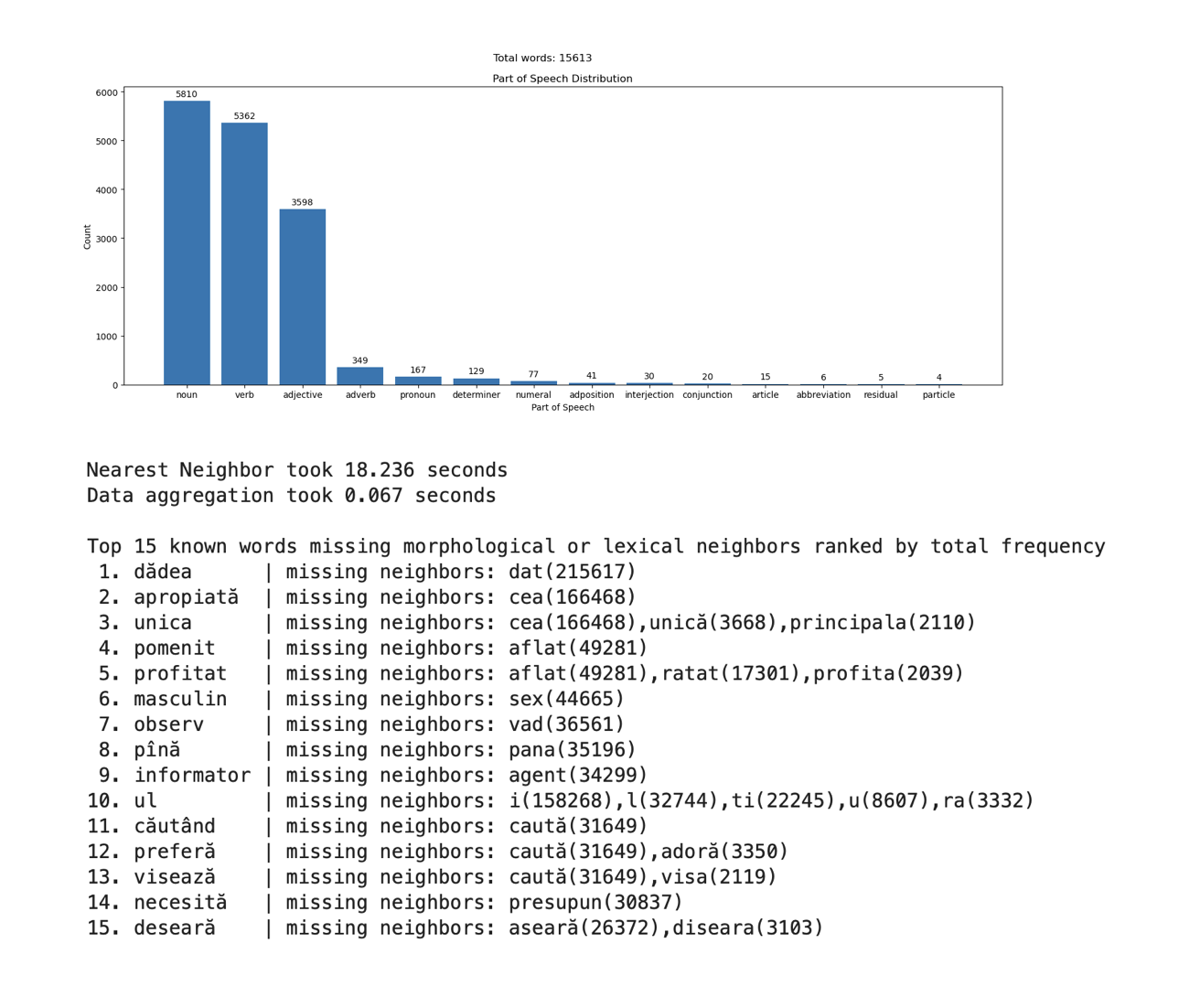
My computer science capstone project exploring how machine learning can identify vocabulary gaps for language learners. The application analyzes a user’s known words exported from LingQ and applies K-Nearest Neighbors on FastText word embeddings to suggest semantically related words that may be missing from their vocabulary.
Key Components
- Parsing and normalizing FastText embeddings, frequency lists, and part-of-speech data from multiple public sources
- Part-of-speech distribution charts, frequency coverage plots, and word clouds built with matplotlib
- Unsupervised K-NN using cosine similarity on 300-dimensional word vectors to find semantically similar vocabulary gaps
Under the hood:
- Python
- scikit-learn
- FastText
- pandas
- matplotlib
- NumPy
- Jupyter Notebook
- Docker
What I Learned
- Working with high-dimensional word embeddings and vector normalization for cosine similarity
- Batch processing large datasets (2M+ word vectors) efficiently with NumPy
- Building interactive Jupyter notebooks
- Validating unsupervised ML models without labeled training data